Indexing就是我們RAG的其中一環的作法,後續會講作用。
講了這麼多的的理論終於來到了實作部份!
先安裝必要的SDK(文件是使用chroma,但為了後續方便我使用pgvector)
pip install langchain langchain_community langchain_openai beautifulsoup4 psycopg2-binary pgvector
建立好後,我們需要有一個postgres DB環境(可使用docker方式建立),建立完後安裝pgvector擴展
CREATE EXTENSION IF NOT EXISTS vector;
接著我們就來跑一下langchian上的code,因為有些方法被棄用了,所以我有小更動一點code!
參考以下langchain圖片:
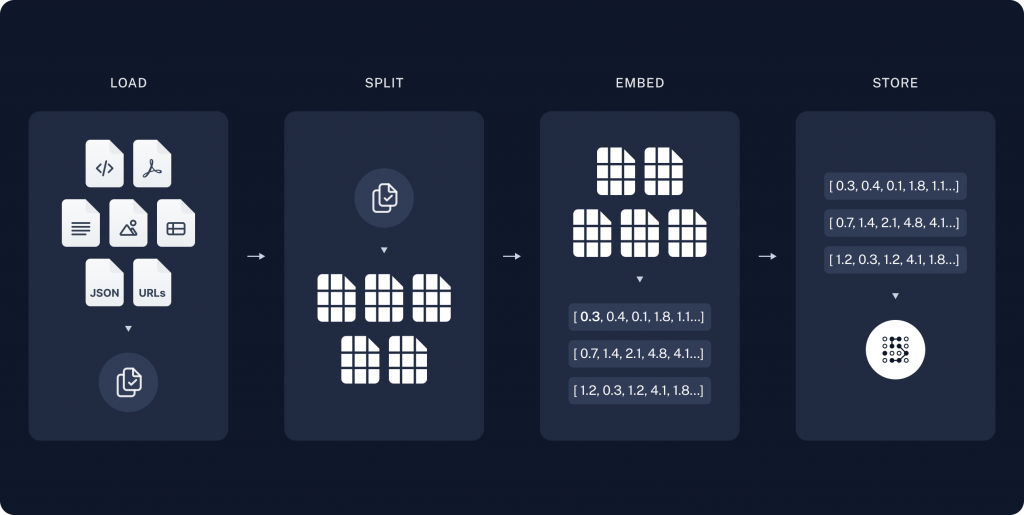
Indexing的順序為
以下為實作的範例:
from langchain_community.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import PGVector
from langchain_openai import OpenAIEmbeddings
import bs4
CONNECTION_STRING = "postgresql://benson:benson@localhost:5432/postgres"
# 1. load data
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
# 2. spilt documents
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
# 3. pgvector
embeddings = OpenAIEmbeddings()
vectorstore = PGVector.from_documents(
embedding=embeddings,
documents=splits,
collection_name="rag_demo",
connection_string=CONNECTION_STRING,
use_jsonb=True
)
# 4. retriever
retriever = vectorstore.as_retriever(search_kwargs={"k": 6})
# test
query = "What is Task Decomposition?"
retrieved_docs = retriever.invoke(query)
print(f"Retrieved {len(retrieved_docs)} documents")
print("First retrieved document content:")
print(retrieved_docs[0].page_content[:300])
看來可以成功的把git文件轉成load data,並且經過RecursiveCharacterTextSplitter切成1000個chunk並且用chunk_overlap讓句子更有連續性,後續利用OpenAIEmbeddings轉成向量及使用PGVector這裡目前只有使用from_documents方法實作取出變數尚未存入資料庫,第四步驟以後是測試我們可不可以正常使用,明天會正式提到Retriever 並且也會使用LLM來實作完善整個RAG機制!

